
Introduction
Memory safety bugs are inevitable in software written in low-level programming languages. A recent report suggests that roughly 70% of all security bugs found in Chrome are memory safety bugs and about 70% of all security updates for Microsoft products addresses memory safety bugs. The number aligns with my observation for the Linux kernel; my analysis indicates that about 67% of all fixed bugs tracked by Syzbot are memory safety bugs.
Memory safety bugs provide attackers the ability to corrupt memory, which results in the potentiality of exploitation. Researchers from academia and industry have been fighting against memory safety bugs for years. Given the nature that programs written in low-level programming languages inevitably introduce memory safety issues, many approaches have been proposed to mitigate the exploitation of memory safety bugs. Such proposals have also been made for the Linux kernel.
The Linux kernel is a fast-moving project with plenty of options to enable various hardening aspects. Many of which have demonstrated their effectiveness against exploitation. For example, Kernel Adress Space Layout Randomization (KASLR) randomizes the kernel address space at boot time, exploitation that wants to achieve control flow hijacking has to leak the kernel slide. As a result, most of the time attackers have to find another vulnerability which is able to leak kernel information to bypass KASLR. HARDENED_USERCOPY, which checks the memory copy using copy_from/to_user to avoid invalid memory copies that overflow the heap object or stack buffers, has been enabled by default in Debian and Ubuntu. Although there is no obvious evidence that this mitigation defends well against memory overflow bugs, it to some extent eliminates the potential overflow or overreading using the user copy channels. SLAB_FREELIST_HARDENED obfuscates the freelist pointers for slab, making it hard for attackers to hijack the allocation. Although the security guarantee of freelist hardening provided in the upstream kernel was weaker for some time, exploitation that wants to overwrite freelist pointers requires some knowledge about the runtime information (e.g., the heap address or the obfuscation value). SLAB_FREELIST_RANDOM randomizes the freelist order for new slab pages to mitigate heap overflows by reducing the predictability of the slab, with the result being that attackers cannot guarantee that two allocations on heap will be adjacent, hence reducing the stability of exploiting heap overflow bugs. Both of these freelist hardening options are enabled by default in many Linux distros (Debian, Ubuntu, Fedora, etc). In addition to software hardenings that mitigate exploitation, hardware features are also used to harden the Linux kernel. SMAP and SMEP are two well-known hardware features on the x64 platform. SMAP prevents kernel from accessing userspace data while SMEP hinders the attackers from executing userspace code in kernel mode. With these two hardware features, attackers have to put their payload in kernel space.
However, even with the presence of various exploitation mitigations in the Linux kernel, a memory corruption with 2 zero-bytes overflow on the heap is already powerful enough to perform exploitation that bypasses all the mitigations. This implies two messages to the community: 1. Exploitation of memory safety bugs is hard to mitigate. The exploitation techniques have been advanced a lot, and the defense side needs to evolve as well to match the advance of attack. 2. There is some missing hardening in the Linux kernel, which enables attackers to increase their memory-overwriting ability easily. (e.g., from 2 zero-bytes overwriting to code execution).
In Andy Nguyen’s exploitation of the above-mentioned 2 zero-bytes overflow, he leveraged the ability of the overflow to overwrite the lower bytes of a data pointer. As the pointer is corrupted, it references an object abnormally. The object is freed when invoking the free to the data pointer, leaving a use-after-free on that object. The use-after-free then be used to achieve leaking kernel information, and eventually a successful exploitation with all the mitigations bypassed.
There are several key factors helping increase the memory corruption ability from the limited overflow to a successful exploitation. First, the attacker can place any victim object right after the vulnerable object as long as they share the same cache. As such, attackers corrupt pointers in the victim object and transform the overflow to a use-after-free primitive after adding an abnormal reference to an object. Second, the use-after-free on a particular type of object can also be transformed to another type of object if they share the same cache. The exploitation transforms the use-after-free obtained from overflow to another object with properties that allow attackers to read and write on that object, leading to a kernel leak and control flow hijacking.
In general, memory layout manipulation is one of the most important steps in exploitation of the Linux kernel. It helps the attacker achieve the desired memory layout and enables overwriting the victim object given an overflow vulnerability. Other than that, they could reclaim the vulnerable object with another type of object when exploiting use-after-free vulnerabilities. With the desired memory layout in kernel, the attacker can overwrite critical data filled of victim objects to increase the ability of memory corruption.
Although many mitigations have been developed to destabilize memory layout manipulation, they are fragile and easy to bypass when it comes to sophisticated exploitation techniques. For example, SLAB_FREELIST_RANDOM randomizes the freelist order to destabilize the exploitation of heap overflows. It becomes useless when the technique of heap grooming is applied. Basically, heap grooming starts from allocating a bunch of victim objects and then frees some of them. The vulnerable object will be adjacent to the victim object after allocating the vulnerable object that reclaims the memory slot of the freed victim object. As most of the allocations for heap objects in the Linux kernel are in the general caches, it allows two different types of objects to become adjacent to each other, as well as allows reclaiming a freed memory slot using another type of object. So, the attacker always has the chance to achieve desired memory layouts despite the presence of randomization. In the upstream Linux kernel, there is no effective hardening that can help mitigate the memory layout manipulation. Vulnerabilities with a very limited overwrite primitive (e.g., 2 zero-bytes overwrite) are powerful enough to demonstrate the exploitability.
However, developing a realistic mitigation against memory layout manipulation is hard. Hardening that prevents memory layout manipulation has to change the way that current memory management works, which could potentially influence the performance of memory management. This then affects the performance of the whole system, as the memory management has huge impact on the overall performance of the Linux kernel. There has been a proposal for mitigating memory layout manipulation, which is to quarantine the freed heap objects to prevent the immediate reclaim of the object. However, the performance cost, in the worst case, is very heavy on some benchmarks. In addition to that, the security guarantee is not promising. Since the quarantined object will be released to freelist eventually, attackers still are very likely to reclaim the object with a sophisticated strategy.
AUTOSLAB
What is AUTOSLAB?
Different from quarantining freed kernel heap objects, grsecurity developed an isolation-based approach where each generic allocation site (calling to k*alloc*) has its own dedicated memory caches. As such, two different object types will be isolated from each other since they are allocated from their own dedicated memory caches. Also, the freed object can only be reclaimed by the same type of objects. The idea is implemented as a kernel hardening, AUTOSLAB, which creates memory caches and instruments heap allocation functions automatically to make sure each allocation of heap objects is from their dedicated memory caches without too much manual modification to the kernel source code.
Overview of security benefits of AUTOSLAB
Compare AUTOSLAB’s isolation-based approach with the heap quarantine approach from the security perspective: the heap quarantine approach has no guarantee that two different objects will not be adjacent, which leaves a window for the attackers to exploit heap overflow vulnerabilities. Besides, attackers might be able to learn the pattern of recycling the quarantined heap objects (e.g., exhausting memory or filling up the quarantine slots) to force the reuse of them, and then reclaim the freed memory by spraying objects. In this regard, quarantining heap objects has no guarantee of effectiveness when it comes to sophisticated exploitation techniques. Whereas isolating objects in different caches, by design, prevents the reclaim of the freed vulnerable object with a spray object that is different from the vulnerable one. This is because the allocation of different object types will always go to their own dedicated caches. Besides, putting a different victim object right after the vulnerable one in the same cache will not be possible due to the isolation, where only two objects of the same type can be adjacent to each other. In the next section, I will describe my detailed security evaluation for AUTOSLAB.
Evaluating AUTOSLAB
The evaluation was done during my 3-month internship at Open Source Security, Inc. I was asked to publish whatever I found for AUTOSLAB (either good or bad). To have a systematic evaluation, AUTOSLAB was evaluated from the following aspects:
-
The completeness of isolation implemented in AUTOSLAB. Incompleteness of isolation means that some objects are not isolated into different caches. If two object types are not isolated and can be allocated into the same cache, the design goal of isolation is not fulfilled. Therefore, the security guarantee cannot be provided.
-
The possible attacks to abuse the isolation. The mechanism used to enforce the isolation is based on the memory caches in the kernel slab allocator, which is not designed for security purposes. Here, I discuss how the attackers could potentially abuse the isolation mechanism to conduct attacks and how AUTOSLAB mitigates these attacks.
-
The security improvement of AUTOSLAB. Compared to using general caches without isolation, AUTOSLAB mitigates the memory layout manipulation for exploitation. Here, I evaluate how resilient AUTOSLAB is against memory layout manipulation when it comes to different types of memory corruption.
-
The performance overhead and usability of AUTOSLAB. Security is not the only factor to consider when adopting a mitigation. I will also evaluate the performance overhead/gain introduced by AUTOSLAB and discuss its usability when deploying AUTOSLAB.
1. Completeness of isolation
As AUTOSLAB automatically converts calls of allocation functions to dedicated functions that allocate heap objects from dedicated memory caches, the potential incompleteness of isolation comes from two conditions: 1) the allocation functions to be converted are not included in AUTOSLAB. 2) the call statements of the allocation functions are not identified and thus are not converted by AUTOSLAB.
Identifying allocation functions
In addition to the standard allocation functions like k*alloc*, there exist some wrappers of k*alloc* in the Linux kernel (e.g., sock_kmalloc).
void *sock_kmalloc(struct sock *sk, int size, gfp_t priority)
{
...
mem = kmalloc(size, priority);
if (mem)
return mem;
...
}
The wrapped allocation function, in this case, is used to allocate memory for different sock options. It is called in different functions and the allocated memory is cast to different types of objects.
int ip6_mc_source(int add, int omode, struct sock *sk,
struct group_source_req *pgsr)
{
...
struct ip6_sf_socklist *newpsl;
...
newpsl = sock_kmalloc(sk, IP6_SFLSIZE(count), GFP_ATOMIC); [1]
...
}
static int __ipv6_sock_mc_join(struct sock *sk, int ifindex, const struct in6_addr *addr, unsigned int mode)
{
...
struct ipv6_mc_socklist *mc_lst;
...
mc_lst = sock_kmalloc(sk, sizeof(struct ipv6_mc_socklist), GFP_KERNEL); [2]
...
}
When the wrapped allocation function is not handled well, different types of objects will be allocated into the same cache. This is because only kmalloc inside sock_kmalloc will be converted. When different callers invoke calls to sock_kmalloc, they will call to the same converted allocation function and the memory will be allocated from the same memory cache. To handle this problem, AUTOSLAB inlines the wrapper allocation functions so that there will be different call statements to kmalloc in the caller (e.g., ip6_mc_source and __ipv6_sock_mc_join). The inlined call statement of kmalloc, in different callers, will be converted to a dedicated allocation function of AUTOSLAB, respectively, thus isolating the objects in different caches. As the wrapper functions are generally small, inlining the wrappers does not increase the size of the binary too much.
To find the wrappers like sock_kmalloc, I designed and implemented a static analysis tool to identify the candidate functions. The property of candidate functions should satisfy the following conditions: 1) the function contains a statement that calls the allocation functions. 2) the return value of the allocation should be returned. 3) the function has at least two callers.
Available at this link are the wrappers found by the static analysis tool; all the findings have been reviewed manually.
One weakness of AUTOSLAB is that it doesn’t have awareness of newly-introduced wrapper functions. It relies on manual effort to annotate the wrappers and inline them. But given that introducing new wrappers is rare, it will not affect the whole effectiveness of AUTOSLAB too much.
Converting allocation functions
Another potential source of incompleteness comes from the situation where the allocation function is not converted. This happens when there are indirect calls to the allocation functions (e.g., kmalloc). To make sure there are no such unconverted indirect calls to the allocation functions, I performed static analysis on the kernel binary compiled with allyesconfig. Since all the calling to the allocation functions are converted to the dedicated allocation function of AUTOSLAB, there should not exist any reference to them. My static analysis results confirmed this and ensured there are no such indirect calls.
2. Attacks to abuse the isolation mechanism
AUTOSLAB leverages the mechanism of slab caches in the kernel’s heap allocator to ensure the isolation. Since the design of the slab cache is not for isolation but for performance, it has some weaknesses that could be exploited for exploitation purposes. The isolation mechanism inherits those weaknesses from slab caches, which could be utilized to abuse AUTOSLAB. Here I discuss what they are and how AUTOSLAB mitigates those attacks.
Cross-cache overflow
When a dedicated memory cache is created for a specific type of object, only that type of object will exist in that cache, thus preventing objects with different types from being adjacent. However, slab pages of different slab caches can be adjacent to each other. When slab A is adjacent to slab B, the object at the end of the slab A becomes adjacent to another object at the beginning of slab B. As such, there is a chance that attackers can place a slab page with any type of victim object right after the slab page of vulnerable objects and overflow the victim object to perform attacks.
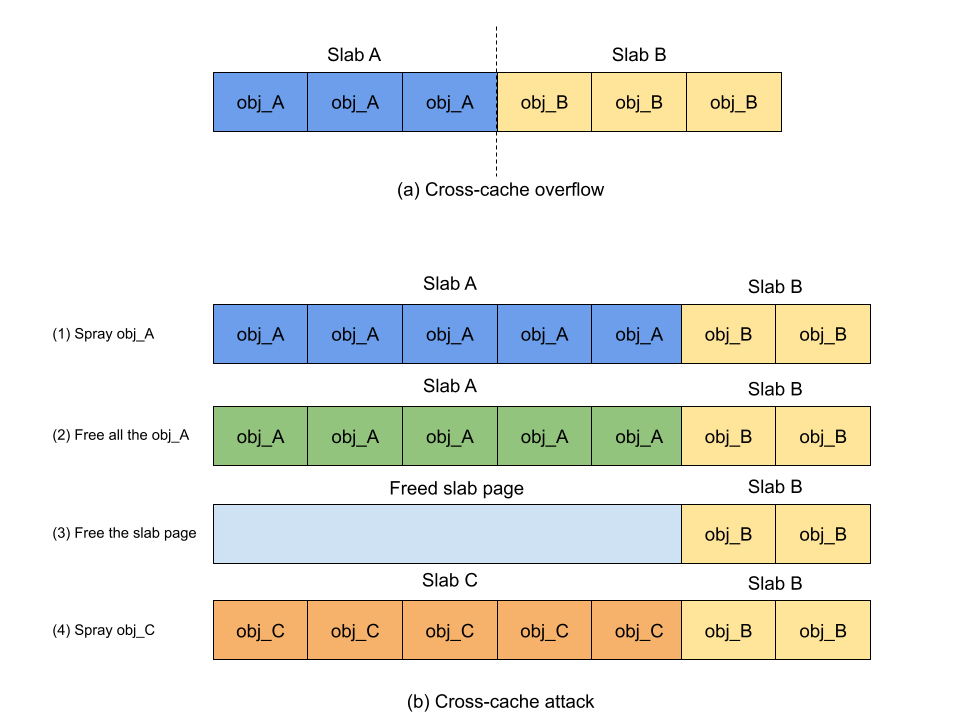
Cross-cache attack
When a slab page is freed to the buddy system, it will be reused at some point later given that the memory page should be recycled by the kernel. The technique of cross-cache attack is to free all memory slots in the slab page, forcing the slab page to be freed. Then, spray another type of object to allocate new slab pages to reclaim the freed slab page. If the attack is successful, the memory of freed objects will be occupied by another type of object. The practice of cross-cache attack used to be rare in exploiting memory safety vulnerabilities in the Linux kernel. It’s not only unnecessary but also unstable to do it in general caches. Especially for frequently used general caches, the attack suffers noise from uncontrollable allocation. For instance, when there is an unknown allocation coming from the kernel, the freeing of all memory slots in the slab page fails, making it impossible to reclaim the slab page by another slab page. Compared to performing cross-cache on general caches, it has nearly no noise when it comes to dedicated object caches. This is because each allocation will go to its own cache, including the unknown allocation from the kernel, which reduces the possibility of unknown allocation in the cache. As such, attackers can reliably free the slab page of the dedicated caches to perform the cross-cache attack.
The cross-cache attack to dedicated memory caches not only makes it more reliable to reclaim the free memory slot using a different type of object, but also loosens the restriction of choosing candidate spray objects. In general caches, reclaiming the memory slot of a freed vulnerable object implies a size requirement for the spray object. That is, the size of the spray object should fit in the cache. Using the cross-cache attack, the spray object can be arbitrary as long as the order of spray slab page is not bigger than the that of the target slab page. For example, the order of the slab page for struct timerfd_ctx (0xd8 bytes) is 3, so an attacker can use struct ip_mc_socklist(0x30 bytes) whose order of slab page is also 3 to perform a cross-cache attack. As the buddy system will split high order pages to satisfy small allocations, the attacker can also spray any object whose order of slab page is smaller than 3. As a result, isolating objects in dedicated memory caches gives an attacker more options to choose spray objects.
Countermeasures in AUTOSLAB
a. Adding a random offset at the beginning of slab pages
AUTOSLAB adopts the approach of adding a random offset at the beginning of slab pages. The size of offset ranges from 8 bytes to the size of an object in the cache. The offset serves two purposes. First, whenever attackers are able to achieve cross-cache overflow, the random offset randomizes the layout of the victim object as how many bytes should be used to fill up the offset is unknown to attackers. Once the payload does not fit in the right spot of the victim object, the exploitation may fail due to the imprecise overflow. Second, the random offset may misalign the payload as well when exploiting use-after-free vulnerabilities. Although cross-cache attack enables attackers the possibility of reclaiming the memory slot of a vulnerable object using another type of object, attackers have no idea about the detailed object layout in the cache. In other words, the memory address of the vulnerable object is unknown to attackers. Hence, attackers have to spray the payload hoping that the payload will overwrite the content of the vulnerable object. However, the presence of a random offset will easily misalign the payload with the vulnerable object, preventing attackers from occupying the vulnerable object precisely.
However, the misalignment of the vulnerable object and the spray object could be abused to achieve another type of exploitation. Specifically, for use-after-free vulnerabilities, the dangling pointer will reference to the middle of the spray object because of the misalignment (see the figure below). If the attacker has the ability to free memory again through the dangling pointer, the allocator will free the spray object from the middle eventually, which will free part of memory belonging to the following object. As such, there will be an overlap between two objects. This gives the attacker the potential to perform an attack through the overlap. Hence, in AUTOSLAB, the random offset cooperates with another hardening measure that prevents invalid frees targeting the middle of objects, ensuring that the object being freed is legitimate.
In some cases, the random offset will not be effective. For example, the victim object can probe the overflow. The attacker can overflow the victim object partially and probe how many bytes have been overwritten to the object. As such, the attacker can keep trying and probe the size of random padding and can trigger the overflow reliably and precisely. Other than that, the random offset will not be working if the victim object works for blind overflow. If the victim object is full of function pointers, due to minimum allocation alignment, the attacker can overwrite with a bunch of function pointers without any side-effect.
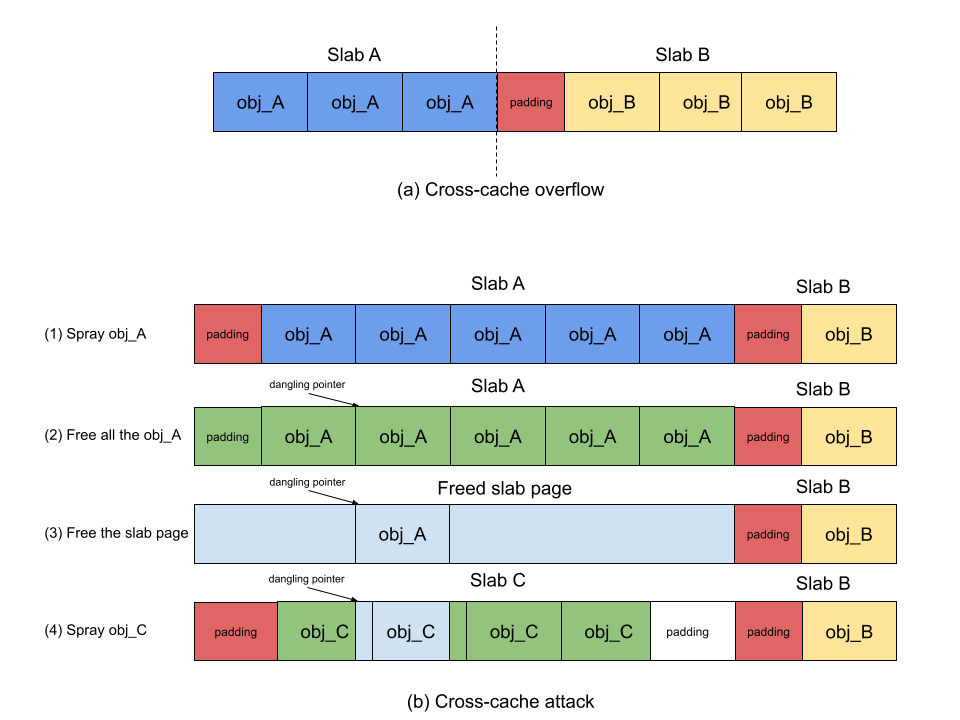
b. Adding freed slab pages to tail of buddy allocator freelist
When a slab page of a given order is fully freed up, adding it to the tail of the buddy allocator's freelist can reduce the reliability of an attacker controlling the specific pages needed for a use-after-free or overflow.
c. Dynamically increasing slab page order
Combined with the change above, this forces an attacker trying to groom the heap to exhaust and fragment higher order memory pages before the lower order target pages can be used in an exploit. The side-effects of such heap grooming attempts decrease their success rate.
3. The security improvement
With the countermeasures adopted in AUTOSLAB, I will discuss how the isolation provided improves security. I collected the public exploits and write-ups for the past 5 years of Linux kernel vulnerabilities in the dataset to evaluate what AUTOSLAB can mitigate and what it cannot.
The security improvement of AUTOSLAB comes from isolating different types of objects into different memory caches, which restricts attackers’ ability to manipulate the memory layout. In general, there are two categories of memory manipulation – adjacent placement of two different types of objects and reclaiming the memory of a freed object with another type of object. As such, the security improvement of AUTOSLAB is evaluated based on the exploitation that requires these two types of memory layouts.
Exploiting heap overflow vulnerabilities
Exploiting heap overflows in general caches usually involves placing a victim object fitting in the same cache in the memory range where the vulnerability can overflow, and then overwriting some critical data fields to fulfill the exploitation goals. In AUTOSLAB, this exploitation procedure has changed due to the memory layout manipulation being much more restricted. In the following, I will describe how restricted it is and what property of the vulnerability is required to achieve successful exploitation.
a. In-cache overflow
This type of overflow belongs to the cases that always overwrite the memory region within a single cache. Compared to using general caches without isolation, some conditions need to be satisfied to achieve successful exploitation with AUTOSLAB.
i. The vulnerable object can be exploited as the victim object.
The vulnerable object itself has some critical data (e.g., data pointer) that can be utilized to perform exploitation. In this case, no memory manipulation is required for exploitation. According to my investigation of the public exploits and write-ups for the Linux kernel in the past 5 years, only CVE-2016-8633, CVE-2016-9793 and CVE-2017-1000112 satisfy this condition among 18 heap overflow vulnerabilities.
ii. Corrupting the heap allocator’s freelist
Attackers might overwrite the freelist pointer to abuse the kernel heap allocator to write anywhere they want. This is intuitive and has been a well-known technique in the real world. However, it requires the vulnerability to provide the ability of leaking to achieve this goal given upstream already has a hardening called SLAB_FREELIST_HARDENED against this exploitation technique. In practice, the implementation of freelist pointer obfuscation in upstream is weak; as we will show in the following, the attacker with an overread ability can bypass this hardening without knowing the random value and heap address of the object. With the technique applied, the attacker can craft a fake freelist pointer to abuse the slab allocator, achieving arbitrary write ability.
b. Cross-cache overflow
This type of overflow belongs to the case that will overwrite memory regions beyond the cache. If the vulnerable object does not have critical data to be leveraged, the attackers can put a victim slab page right next to the slab page of the vulnerable object and trigger the overflow to overwrite the victim objects in another slab page.
i. The vulnerable object is resilient against overflow
To achieve cross-cache overwrite, the attackers can randomly choose a vulnerable object and trigger the overflow. The side-effect of blind overflow is that other objects in the cache may be corrupted mistakenly, making the kernel unstable, unless the vulnerable object is resilient against overflow, i.e., overflowing the vulnerable object will not crash the kernel in the following exploitation procedure. The possible situation for this is that the objects get allocated in the cache but will not be used by the kernel if users do not invoke any operations on it. However, as attackers have no idea about the memory layout in the cache, i.e., how many bytes should they overflow to the adjacent slab page, the attackers need to try their best luck to trigger the overflow from a vulnerable object that is close enough to the victim object if the size of overflow is limited. The attackers also need to take the offset at the beginning of the slab page into consideration. Otherwise, the exploitation may fail if the overflow is misaligned with the victim object.
ii. Trigger the overflow from the end of the slab page
Attackers can also trigger the overflow from the end of the vulnerable slab page and reliably overflow to the adjacent slab page. This requires the attackers to have the ability of probing the detailed object layout in the cache, i.e., which vulnerable object is at the end of the slab page. The conditions are:
- The vulnerable object can be used to probe the position of the overflow. The attackers can partially overwrite the adjacent vulnerable object and probe which one has been overwritten, thus determining the cache layout: which one is behind which one.
- The vulnerability has the overread ability. The attackers can utilize the ability to leak the memory content and thus probe the memory layout in the cache, identifying the vulnerable object at the end of the slab page. This ability also empowers the attacker to bypass the random offset at the beginning of the slab page.
Alternatively, attackers might try their best luck to start the overflow from the end of the cache. They will have more luck if the number of slots in the cache is smaller. However, attackers have no idea about the start offset of the adjacent slab page, so they will need to probe the layout of the victim slab page to avoid a misaligned overflow.
iii. The vulnerable object allocated by the buddy allocator
There are two scenarios where the vulnerable object will be allocated by the buddy allocator. The first one is when the object is allocated by the buddy allocator explicitly; the second one is when the size requested to kmalloc is larger than KMALLOC_MAX_CACHE_SIZE, the allocation will pass to the buddy allocator. AUTOSLAB uses caches to allocate memory instead of using the buddy allocator when the size requested is larger than KMALLOC_MAX_CACHE_SIZE. As such, AUTOSLAB eliminates the possibility of allocating objects using the buddy allocator implicitly.
If the vulnerable object is allocated by the buddy allocator, attackers can allocate a victim cache adjacent to the vulnerable object and can always overwrite the victim object without any side-effect. However, unless the victim object is allocated by the buddy allocator as well, the attacker needs to guess the random offset at the beginning of the victim slab page if the overread ability is not provided.
The only recent examples of this I found were CVE-2017-7308 and CVE-2021-32606. These are overflow vulnerabilities that allocate the vulnerable object using the buddy allocator. AUTOSLAB cannot defend the exploitation of these vulnerabilities if the attacker overwrites a victim page allocated by the buddy allocator.
Case Study
Compared to using generic caches, heap overflows become harder to exploit in AUTOSLAB. Special properties are required to defeat AUTOSLAB as I discussed above. (e.g., the overread ability or the vulnerable object is allocated by buddy allocator) Here, I show a case study of how AUTOSLAB mitigates the exploitation of a heap overflow.
The vulnerability occurs when the memset is called to initialize the memory with size larger than that of the object. As such, the primitive of the bug is to write bytes of zero out-of-bounds. In Andy Nguyen’s exploitation, this primitive is used to overwrite the lower bytes of the next pointer in the object msg_msg, so the corrupted next pointer will reference an object improperly. When the object the next pointer references is freed, the memory is still accessible from the next pointer through the object msg_msg. At this point, the vulnerability is transformed from a limited overflow to a use-after-free. However, to overwrite the next pointer partially, the msg_msg object should be adjacent to the vulnerable object that the overflow happens from.
In AUTOSLAB, the only chance of placing these two objects adjacent is to place their slab pages adjacent. In addition to that, the overflow should start from the vulnerable object at the end of the slab page. This is challenging because the attacker has no idea which vulnerable object is the last one in the cache. The attacker could also try another exploitation approach discussed above, however, the vulnerability doesn’t have the required property. Besides, even though the attacker achieved desired memory layout and triggered the overflow from the right place luckily, they no idea about how many bytes are needed to overwrite the lower bytes of the next pointer precisely with the presence of the random offset at the beginning of the slab page. If any pointer is overwritten incorrectly, the exploitation cannot continue. As such, AUTOSLAB can effectively mitigate the exploitation of this vulnerability.
Exploiting use-after-free vulnerabilities
A use-after-free vulnerability, in general, has a dangling pointer referencing the memory of the vulnerable object freed. In generic caches, the attackers usually find a spray object that fits in the cache of the vulnerable object to reclaim the memory of interest. As such, two different types of objects are overlapped. By manipulating the data field through one of them, the attackers can overwrite/overread some critical data fields in another object, thus they can achieve their exploitation goals. In AUTOSLAB, the way of reclaiming memory is changed due to the isolation mechanism adopted. In the following, I will describe how this change affects the exploitation.
a. Use the vulnerable object as the spray object
Isolating different types of objects into different caches prevents two different types of objects being in the same cache. As such, the attacker cannot use a different type of object to reclaim the memory slot of the freed vulnerable object. However, once the vulnerable object can be used as the spray object, the isolation will not work against exploitation. This requires the vulnerable object to have some data fields that can be used for data-only attacks. For example, the vulnerable object contains some data that only privileged users can access. By freeing the vulnerable object spraying another that does not have permission checks in same the memory spot, the attacker will be able to read the data improperly. From the dataset, I only found one vulnerability (CVE-2016-4557) that provides such property.
b. Use another type of object as spray object
The isolation prevents direct reclaim of freed memory of the vulnerable object using a different type of object. However, the attacker can still utilize the cross-cache attack discussed above to reclaim the freed memory and place a spray object in the place of the vulnerable object. To perform the cross-cache attack, the vulnerable object should be able to be allocated and freed arbitrarily by attackers. In some scenario where the vulnerable object is allocated before the exploitation happens, the cross-cache attack could not be performed successfully.
With generic caches, after reclaiming the memory of the vulnerable object, the attacker can overwrite some fields in the object precisely since the objects start from the same memory address. However, with the presence of “random offset” and “prevent invalid free” in AUTOSLAB, even though the attacker is able to perform a cross-cache attack that reclaims the memory of the vulnerable object, they not only have difficulty in overwriting the critical field in the object precisely, but also cannot free the middle of the spray object through the dangling pointer.
To achieve successful exploitation in AUTOSLAB, it requires the vulnerable/spray object to be resilient against overwriting. In other words, the kernel will not crash even though the object is corrupted arbitrarily. Assuming the vulnerable object is an object containing a function pointer, the attacker can spray with the target address to overwrite the function pointer. Subsequently, the function pointer can be dereferenced without causing a kernel crash. It also works if the use-after-free provides the ability of overwriting, in which the attacker can spray a spray object containing a function pointer. As long as the spray object is resilient against overwriting from the vulnerable object, the attacker can hijack the control flow and perform attacks.
Another property of the vulnerable object that helps the exploitation in AUTOSLAB is that the vulnerable object has the ability of leaking. With the leaking ability, the attacker can probe the offset of the spray object to the vulnerable object and then overwrite the data precisely. However, this also requires that the spray on the vulnerable object will not affect the leak ability of the vulnerable object. i.e., the kernel will not crash after spraying.
Compared to exploiting in generic caches, the exploitation in AUTOSLAB has more restriction on the properties of the vulnerable object, which indeed increases the bar of exploitation.
c. The vulnerable object is allocated by the buddy allocator
AUTOSLAB works on objects that are allocated by the SLAB/SLUB allocators. Allocations that go to the buddy allocator are out of scope. As AUTOSLAB will not use the buddy allocator to allocate memory even if the size requested is very large (larger than KMALLOC_MAX_CACHE_SIZE), the vulnerability in this category should have a vulnerable object allocated by the buddy allocator explicitly. Looking at the public exploits in the data, I found no use-after-free vulnerability whose vulnerable object is allocated by the buddy allocator.
There are vulnerabilities being exploited on pages, like CVE-2016-5195 and CVE-2018-18281. However, both of them are due to a flaw in the memory manager and are out of scope for this evaluation.
Case Study
The procedure of exploiting use-after-free in AUTOSLAB has changed compared to that in generic caches. Here I use a case study to show the difference.
The vulnerability is due to the flaw in the clone of inet_sock object, where two inet_sock object will reference to the same ip_mc_socklist object after the clone. When one of the inet_sock object is freed, the ip_mc_socklist object will be freed as well, then the reference in another inet_sock object becomes a dangling pointer referencing a freed object.
struct ip_mc_socklist {
struct ip_mc_socklist __rcu *next_rcu;
struct ip_mreqn multi;
unsigned int sfmode; /* MCAST_{INCLUDE,EXCLUDE} */
struct ip_sf_socklist __rcu *sflist;
struct rcu_head rcu;
};
The ip_mc_socklist object is freed through kfree_rcu. After calling to kfree_rcu, the free of the object will be added to the kernel work list and a callback function will be registered in the rcu field. The callback function will be called after the grace period by kernel.
This gives an opportunity to hijack the control flow by overwriting the function pointer in the object after the callback is registered. As such, the exploit first calls the free of the object, then keeps modifying the rcu field hoping that the callback function pointer will be overwritten. This approach also works in AUTOSLAB if the kernel doesn’t have other hardening to prevent the use of maliciously overwritten function pointers, like RAP. In AUTOSLAB, the attacker can first spray many copies of the vulnerable object, then add a reference to one of them by cloning the inet_sock object. After that, free the referenced one along with others just sprayed to free the slab page. At this point, the dangling pointer is referencing the middle of a freed slab page. The attacker then sprays the victim object that is full of function pointers. Although the attacker has no idea about the object layout in the slab page, he can blindly overwrite the vulnerable object given that the misaligned payload will not affect hijacking the control flow. Once the callback is registered, but the function pointer inside is tampered with by the victim object, the attack can hijack control flow when the function pointer is dereferenced.
In reality, the ability of memory corruption is much more powerful than what is demonstrated in the public exploit. With a sophisticated exploitation strategy applied, the vulnerability itself can be exploited with all the mitigations that many popular distros enable. (e.g., KASLR, KPTI, SMAP, SMEP, SLAB_FREELIST_RANDOM, and SLAB_FREELIST_HARDENED). The exploit would proceed as follows:
- Prepare the context of use-after-free, now we have a dangling pointer to a freed object.
- Spray
msg_msgsegto reclaim the freed object, now the dangling pointer references to themsg_msgsegobject - Free the
msg_msgsegobject through the dangling pointer, now objectmsg_msgsegis freed. - Use
msgrcvwithMSG_COPYflag set to read the content of freed object, since the object was freed bykfree_rcu, a callback function was stored in the object, reading the content of the object leaks the function pointer. - Keep spraying object
msg_msgsegwith the same size as objectip_mc_socklist, making sure the slab page is full of objects. Now, the freelist in that slab page is empty, and we have twomsg_msgsegobjects referencing the same memory. - Free the
msg_msgsegobject that is used to leak the function pointer. Now an obfuscated freelist pointer is written to the object. The value isfp ^ random ^ heap_addr, wherefpis the freelist pointer of the slab page. Since the freelist is empty, the obfuscated freelist pointer becomesrandom ^ heap_addr. Now we can leak this value through themsg_msgsegobject. - With the information leaked, the attacker would be able to craft the obfuscated freelist pointer as
target_address ^ random ^ heap_addrand abuse the slab allocator to write anywhere with anything they want.
With AUTOSLAB, the above-mentioned exploitation strategy cannot work. Although the attacker can use the cross-cache attack to reclaim the memory of the vulnerable object, using the dangling pointer to free the msg_msgseg object will be detected by kernel. This is because the “random offset” added at the beginning of the slab page will misalign the overlap between the vulnerable object and the spray object. Given the vulnerable object doesn’t have the ability of leaking, the attacker is not able to probe the object layout. As such, there will be a misalignment between the vulnerable object and the spray object. If the dangling pointer references to the middle of the spray object, the attacker cannot free the object using the dangling pointer. Otherwise, the invalid free will be detected by the kernel.
4. Performance and usability
Performance
To evaluate the performance of AUTOSLAB, I used iperf to test network throughput, hackbench to test the scheduler, and lmbench to test the overall system performance. The performance evaluation was done on a physical machine with a Intel Core i7-4600U (dual core, 2.10GHz), 16 GB memory, and 500G HDD. Before running any benchmark, I disabled the CPU turbo and SMT for benchmark stability. I also changed cpufreq governor to to performance. The kernel used was Linux 5.12.19 patched with grsecurity. The comparison was performed between a config that enabled the AUTOSLAB feature and another one that does not (baseline).
In the network throughput test, I ran iperf for 5 rounds, with each round being run for 60 seconds. It turns out, on average, the kernel built with AUTOSLAB enabled has 1.2% more throughput than the baseline kernel.
For the scheduler stress test, I used the following command and ran the test for 50 rounds.
hackbench -s 8000 -l 1000 -g 100 -f 10
On average, the kernel with AUTOSLAB enabled runs 0.08% slower than the one without AUTOSLAB.
For lmbench, I ran the benchmark for 10 rounds with the default configuration. Lmbench measures the latency and bandwidth of the system. The results are the following:
| Latency in ms | Baseline | AUTOSLAB | Overhead |
|---|---|---|---|
| Context Switching (2p/0k) | 0.92 | 0.88 | - 4.3% |
| UDP | 8.66 | 9.17 | +5.9% |
| TCP | 11.36 | 10.76 | -5.3% |
| 0K File Create | 6.37 | 6.65 | +4.3% |
| 0K File Delete | 4.43 | 4.77 | +7.7% |
| 10K File Create | 13.29 | 13.62 | +2.5% |
| 10K File Delete | 6.68 | 7.10 | +6.3% |
| Mmap | 91.33 | 91.00 | -0.4% |
| Bandwidth in MB/s | Baseline | AUTOSLAB | Overhead |
|---|---|---|---|
| Pipe | 4122.1 | 4380.8 | -6.3% |
| AF UNIX | 8922.8 | 8933.6 | -0.1% |
| TCP | 5839.1 | 5881.0 | -0.7% |
| File Reread | 6658.1 | 6752.4 | -1.4% |
| Mmap Reread | 12.03K | 11.6K | +3.6% |
| Bcopy(libc) | 8471.9 | 8165.6 | +3.6% |
| Bcopy(hand) | 5375.9 | 5369.8 | +0.1% |
| Mem Read | 9086.1 | 9520.2 | -4.8% |
| Mem Write | 8265.3 | 8045.6 | +2.7% |
Usability
Enabling AUTOSLAB in grsecurity's kernel is simple; what needed is to enable it in the kernel configuration. No additional effort is required.
Conclusion
Memory safety issues in programs written in low-level languages are a critical problem and hard to mitigate against exploitation. Even a limited memory corruption ability (e.g., 2 bytes zero overwrite) would be able to achieve exploitation. AUTOSLAB mitigates exploitation by isolating objects. From a security perspective, AUTOSLAB is not a silver bullet that can mitigate all the issues of memory safety exploitation. Exploiting in AUTOSLAB is still possible if some special properties of the vulnerability are provided. However, with some performance gain, AUTOSLAB hinders memory layout manipulation, with the result being that many vulnerabilities that used to be exploitable become harder to exploit and some even unexploitable. This blog discussed the extent to which AUTOSLAB prevents exploitation, as well as what vulnerability properties are needed for successful exploitation in the presence of AUTOSLAB.